| |
L'ORGANISATION ET L'ARCHITECTURE DE L'INTERNET |
|
|
|
Les protocoles
Quand un utilisateur visualise des pages dans son navigateur, il y a un
échange de données entre sa machine de consultation (client) et la machine
qui lui fournit les pages WEB (serveur).
On peut se représenter cet échange en le comparant au système d'acheminement
Postal. C'est un service à commutation de paquets. Il n' a pas de tronçon
dédié entre les 2 extrémités. L'expéditeur envoie des messages mis dans
une succession d'enveloppes et les envoie sur le réseau local comme on met
une lettre dans une boîte aux lettres.
| Au terme de l'acheminement, le destinataire enlève les enveloppes, celles-ci lui informent successivement qu'il vient de recevoir un paquet IP contenant du TCP qui lui même contient du HTTP. Le message est donc destiné au serveur. | 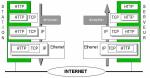 |
Pour se comprendre les machines doivent parler le même langage, respecter certaines règles. Les logiciels respectent donc les mêmes protocoles standards:
- les pages Web sont écrites en format HTML;
- le client Netscape et le serveur Web parlent le même langage : http;
- tcp fiabilise l'échange de données HTTP, en établissant des connexions;
- ip permet d'adresser n'importe quelle machine de l'INTERNET;
- le paquet ip créé par l'émetteur arrive tel quel au destinataire;
- entre temps, il aura utilisé plusieurs moyens de transport;
- sur un réseau local, le paquet sera probablement envoyé dans une trame Ethernet.
| Le tableau ci-dessous présente les principaux protocoles utilisés dans l'intranet/INTERNET |  |
Les paquets expédiés sur le réseau peuvent emprunter des itinéraires différents. Une fois arrivés à bon port, ils sont remis en ordre afin de reconstituer l'information originale. Ce système de transmission est fiable et rapide, mais défie parfois la logique : Un message posté depuis Paris pour Nanterre peut très bien transiter par Los Angeles avant d'arriver à destination...
Pour les connexions ponctuelles d'un particulier chez un prestataire de services relié à l'INTERNET, comme Orange par exemple, deux protocoles sont possibles pour transmettre l'information des machines accédant à l'INTERNET par modem (liaison téléphonique) aux machines physiquement reliées au réseau : le protocole PPP (Point to Point Protocol) ou le protocole SLIP (Serial Line IP).
Les ports de protocoles:
| Pour qu'un client HTTP atteigne un
processus serveur HTTP (httpd) à l'intérieur d'une machine
serveur WEB, il doit atteindre un numéro de "porte" derrière
laquelle il est sûr de trouver un processus httpd. Il existe sur tous les sites WEB un port portant le même numéro et permettant d'atteindre un processus httpd: le port TCP 80. |
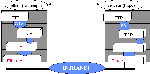 |
Tous les clients HTTP qui se connectent sur le site atteignent les différents
processus httpd en utilisant le même et unique port 80.
Le client HTTP est également accessible par un numéro de port que TCP lui
a affecté de manière aléatoire et qui a été communiqué au serveur
WEB lors de la connexion.
| De la même manière, les autres services de l'INTRANET possèdent des numéros de ports réservés: |
|
| Le serveur HTTP du site de l'intranoo est
accessible sur le port 880 Le numéro de port doit alors être précisé dans l'URL que l'on donne au navigateur. Celui-ci essaie de se connecter par défaut sur le port 80 |
Les réseaux
Une station isolée est généralement reliée à l'internet via un modem. Elle
peut ainsi être rattachée à un réseau local.
Un réseau local est un ensemble de stations dans un ou plusieurs bâtiments
reliées entre elles par un réseau de liaison (exemple : Ethernet ou
Token Ring).
| Pour que les stations de ce réseau puissent être reliées à l'Internet, elles doivent utiliser le protocole TCP/IP et le réseau local doit être relié physiquement à l'internet par un routeur.. |  |
Le routeur permet d'atteindre un autre réseau local ou un réseau d'interconnexion vers d'autres réseaux.
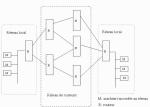
| Voici un exemple de réseau maillé entre 2 réseaux locaux
d'extrémité. La défaillance d'un routeur ou d'une liaison entre 2
routeurs n'interrompt pas la communication entre les 2 sites. Les
routeurs ont pour rôle d'aiguiller le paquet IP sur le bon chemin.
Les routeurs doivent donc connaître l'architecture d'interconnexion environnante. Les informations nécessaires sont stockées dans les tables de routages. |
 |
Celles-ci peuvent être renseignées de 2 manières:
- routage statique: Les tables sont saisies et mises à jour par un opérateur.
- routage dynamique: Les routeurs s'enrichissent mutuellement en échangeant leurs tables de routage. Un routeur doit alors utiliser le même langage que son voisin. Il respecte un protocole de routage (RIP,OSPF,IGRP,BGP4,...).
Ces réseaux d'interconnexion peuvent être régionaux, nationaux ou internationaux. L'ensemble constitue un réseau maillé appelé réseau Internet. Les connexions entre ces réseaux sont toujours assurées par des routeurs. |
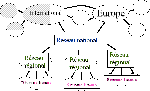 |
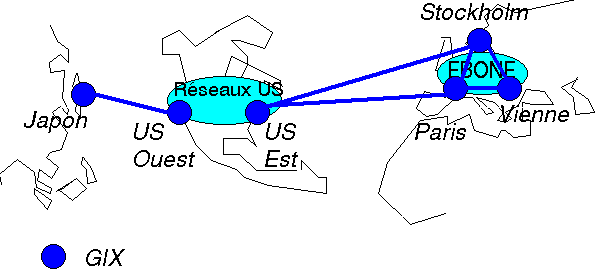
Le trafic de communication entre les réseaux Internet d'Europe (Y compris les réseaux de la recherche) est écoulé au moyen de plateformes d'échange :
-soit des noeuds de communications : Les GIX.
-soit des réseaux fédérateurs ( ex : EBONE).
Les adresses et les noms des machines dans l'INTERNET
Chaque poste connecté sur le réseau Internet possède un numéro de connexion
unique au monde: l'adresse IP (Internet protocol)
Cette adresse (composée de 4 octets (32 bits)) est représentée sous la
forme décimale pointée: 4 nombres décimaux séparés par des points.
Pour communiquer avec une station sur l'Internet, on peut le faire en connaissant son numéro IP, mais ce n'est pas très mnémonique pour les utilisateurs. Il est ainsi préférable d'utiliser des noms. Pour que ça fonctionne, il faut que:
- le nom soit unique dans le monde.
- L'unicité soit garantie par un organisme d'attribution des noms.
- La gestion soit décentralisée pour que les noms de machines puissent être créés localement.
- Il y ait un système automatique pour faire la conversion nom-adresse.
Les noms des stations sur l'Internet ont une forme appelée "domainisée".
L'organisation de l'INTERNET
L'INTERNET n'est pas une organisation formelle. Personne ne le dirige vraiment, mais il existe plusieurs instances dont la tâche consiste à assurer le bon fonctionnement de l'ensemble. Les opérateurs et les fournisseurs d'accès opèrent dans un univers à la fois concurrentiel et coopératif. Tous ont intérêt à s'interconnecter de manière à fournir le meilleur service à leurs clients.
Un certain nombre d'associations, interviennent pour assurer le bon fonctionnement de l'INTERNET, réfléchir à ses problèmes, préparer et accompagner ses évolutions, pour ne citer que les principales :
- L'INTERNET Society (ISOC) a pour objet de faciliter le développement de l'INTERNET à travers le monde.
- L'INTERNET Assignet Numbers Authorithy (IANA) organisme qui représente l'existence d'une forme de pouvoir central dans l'INTERNET : il a pour tâche d'attribuer les adresses INTERNET et les noms de domaine. Il s'agit d'une tâche importante puisqu'elle vise par exemple à éviter que quiconque ne puisse s'attribuer impunément un domaine au nom de la marque d'un des ses concurrents. L'IANA délègue ses attributions à des organismes continentaux (RIPE en EUROPE) et nationaux (Network Information Center NIC FRANCE), associations à but non lucratifs
- L'IETF, INTERNET Engeeners Task Force, organisme établissant les normes techniques.
- Le W3 Consortium est chargé quant à lui du développement et de l'évolution des standards du WEB.
Les proxys
Le WEB, par sa simplicité d'emploi, connaît un très large succès et le trafic qu'il engendre est à la mesure de ce succès.
De plus, il est courant qu'une même page (sur un site US réputé par exemple) soit demandée des dizaines de fois par autant d'utilisateurs différents et emprunte autant de fois les rares et parfois fort encombrés liens transatlantiques.
| Le serveur proxy permet de résoudre en partie ces problèmes. Un proxy est un serveur relais. Il s'intercale entre des clients HTTP et des serveurs d'information. Lorsque vous voulez accéder à une page HTML, votre navigateur va d'abord interroger le serveur Proxy. le serveur Proxy conserve les documents déjà demandés par un autre utilisateur. Si vous demandez la même information (cas très fréquent sur les serveurs populaires), le serveur Proxy vous la transmet directement. Votre ordinateur ne doit donc pas réellement se connecter sur un autre serveur (qui se trouve par exemple aux Etats-Unis ou en Asie) pour obtenir les informations désirées.. Dans le cas ou ces documents sont absents du cache , le Proxy transmet votre demande vers le serveur Web origine. | 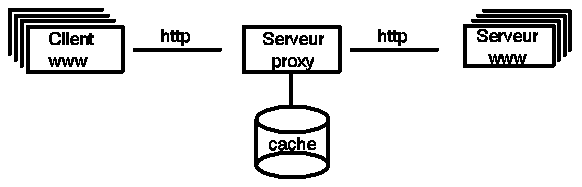 |
La configuration du cache permet de définir une gestion du cache en fonction
de certains paramètres : date de dernière mise à jours du document, durée
de vie max des documents dans le cache, durée de non utilisation d'un document
...
Le serveur va donc, en permanence, scruter son cache et contacter des sites
INTERNET pour des mises à jour.
Ce système, transparent au niveau de l'utilisateur final (si ce n'est la
configuration initiale du logiciel client), devrait offrir des réponses
bien plus rapides pour les données du cache, des réponses sensiblement équivalentes
pour celles non cachées, et globalement une économie non négligeable du
trafic réseau.